Streaming large amounts of data from Elasticsearch

At cosee, we often work in a micro-service architecture. Micro-services are an approach to cut a large application down into manageable parts.
I don’t want to get into too much detail here. The important thing is, that small services, for example written in Java, each do their part of the work and communicate with each other. In a lot of cases, each service has its own data store, for example an SQL-database, an Elasticsearch index or both. Sometimes, data needs to be replicated from one service to another.
The scenario of this post is the following:
- “Service A” needs to replicate part of the data from “Service B”.
- “Service B” holds its data in an Elasticsearch index.
We use data from “geonames.org” (now inactive) to demonstrate our solution. The data-set contains postal-codes from all over the world.
Solution 1: Straight-forward
Services usually use HTTP and message queues to communicate with each other, so the most straight-forward approach to replicate data is this:
- Implement an HTTP endpoint in “Service B”.
- When the endpoint is called, run a search in Elasticsearch return the result.
- Call the endpoint from “Service A” to retrieve the data
- Store the data into the database.
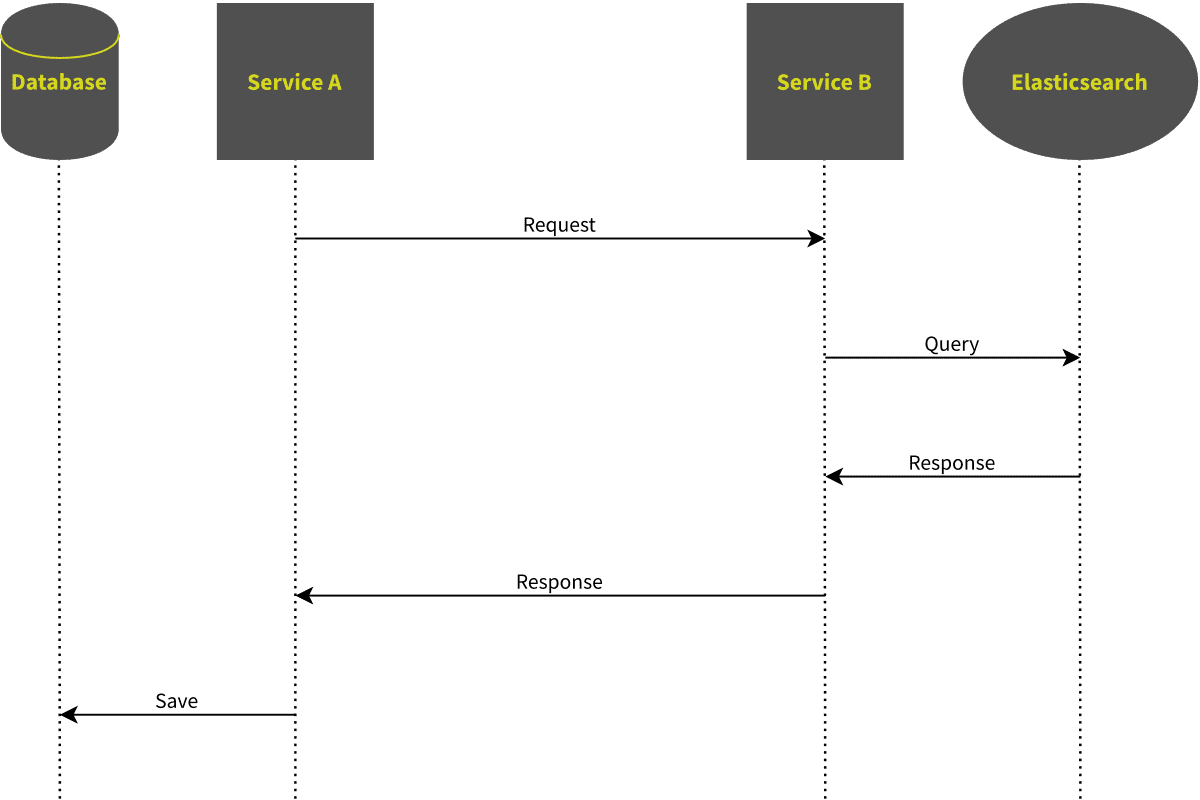
Unfortunately, this does not work for large amounts of data. Elasticsearch usually returns its results in pages. You can specify that you need a page-sizes of 50 items and that you want to get the 15th page. The maximum page size is 10000, so if you need to get more, you need to request the next page. But this approach may give you inconsistent data, because there is no way to guarantee that the index is not updated between your requests.
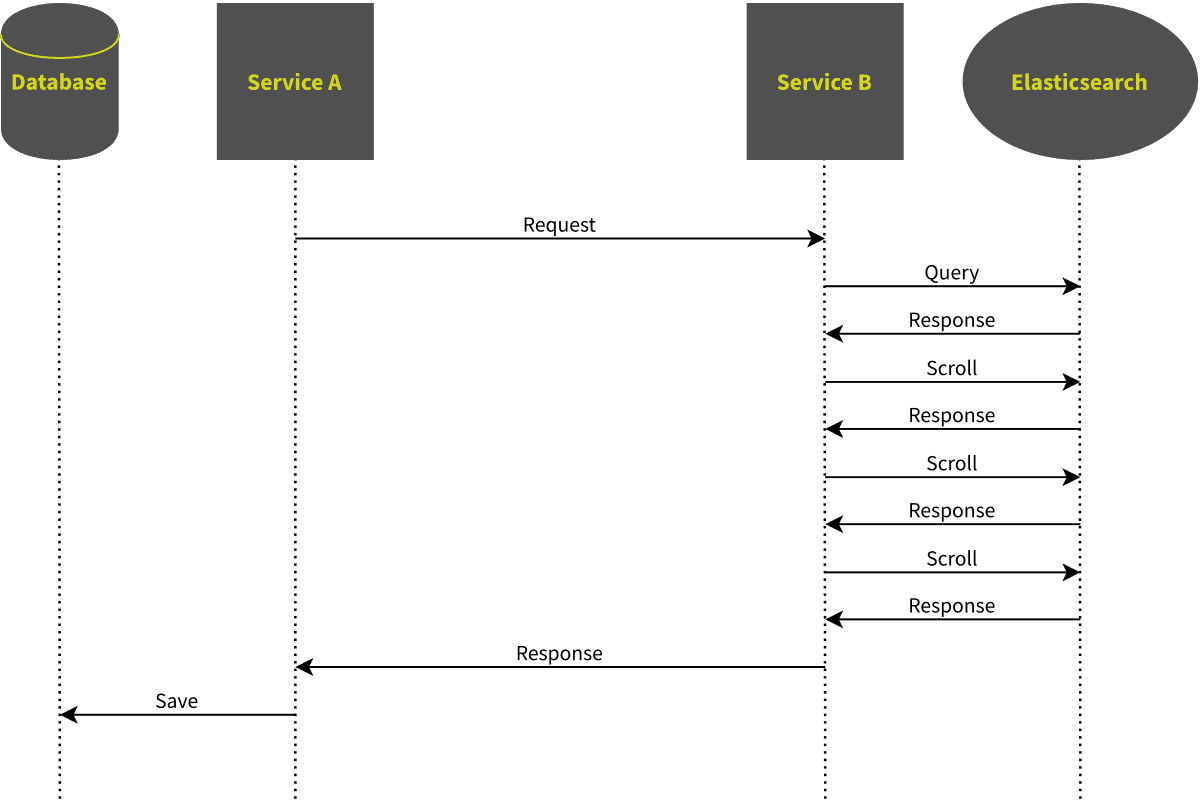
Solution 2: Using the Scroll API
Luckily, Elasticsearch has a solution to this problem: It is called “Scroll-API”. It works like this:
- You add a “scroll”-property to your initial search-request, which has a time-span as value.
- Elasticsearch will internally create a copy of its index. This copy is not modified, and it will live as long as you specify in the “scroll”-property.
- In addition to the search-hits, Elasticsearch will return a “scroll-id” that you can use to access this copy of the index.
- You can then request page after page using your “scroll-id”, each time refreshing the life-time of the index-copy.
- In the end or in case of an exception, you should clear the scroll in order to free memory resources.
This way, you will retrieve a consistent and complete search result. Now instead of just returning a single page of data, we can use the scroll, concatenate the result into a large list and return that list in the response of our endpoint.
Is it really that easy?
No, it is not: During the whole time that the scroll-scan is running, “Service B” does not send a single byte back to “Service A”. In our test-example, it takes about seven seconds for the transfer to start.
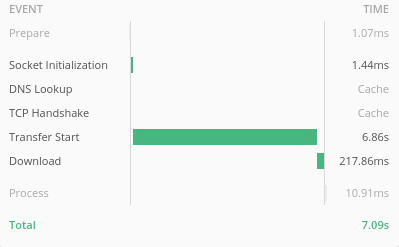
On the first glance, this is may be acceptable. But with a more complicated query and more data, the value may increase up to minutes to complete. If it does, we will get a read-timeout in the client or firewalls may discard the request, which makes this solution infeasible.
Solution 3: Calling back after completing the scroll
Our first attempt to solve this problem was the following:
- After receiving the request, “Service B” simply replies with an “OK”-message
- It then performs the scroll to retrieve all results.
- Once the scroll-scan is finished, it performs a POST request to a special endpoint in “Service A” and posts the collected data.
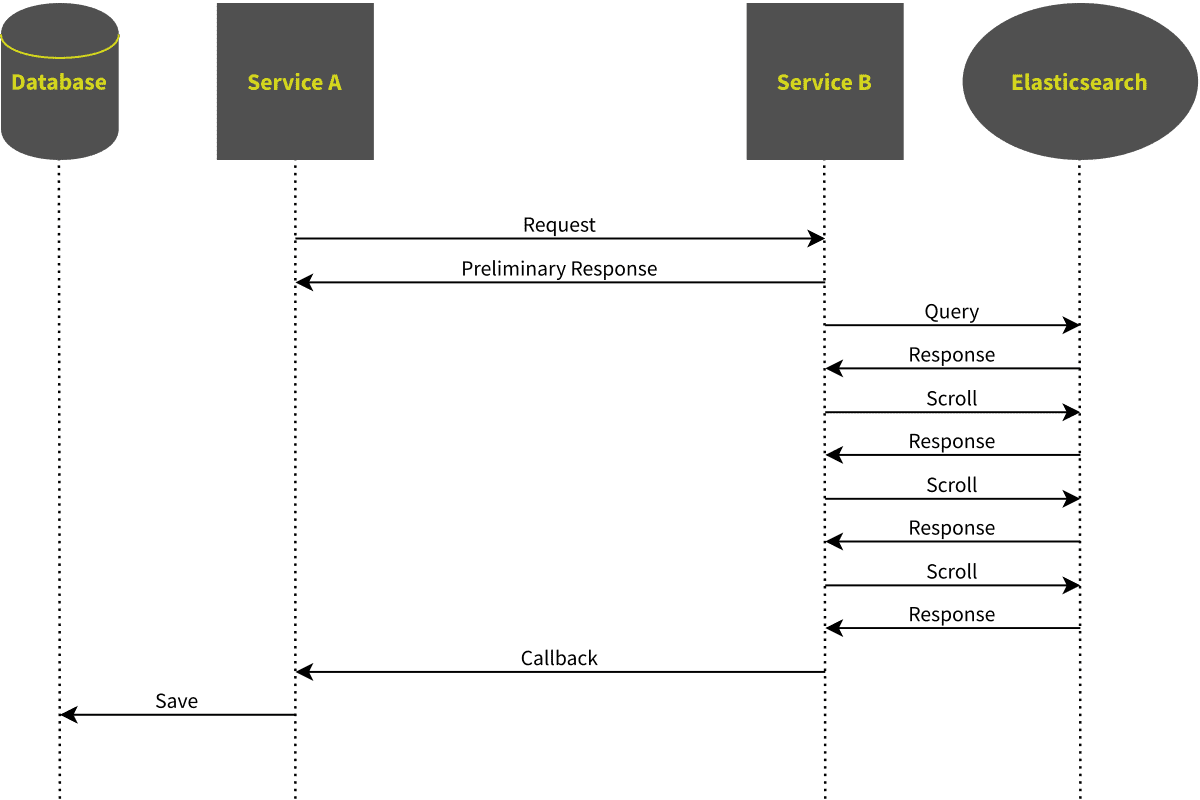
This architecture has lead to a lot of code to manage locks and callback tasks, and it has never really worked. We had to add locks in “Service A” to prevent concurrent modification of the data jobs to remove stuck locks, in case the callback never happens. All in all, this approach has made the code much more complicated and much less robust. In the end, we discarded it in favour of the following solution
Solution 4: Streaming to the max
The main problem with the collecting approach was that the time-to-first-byte was too long. It turns out, that we can reduce this time by writing the data to the response as soon as it is available.
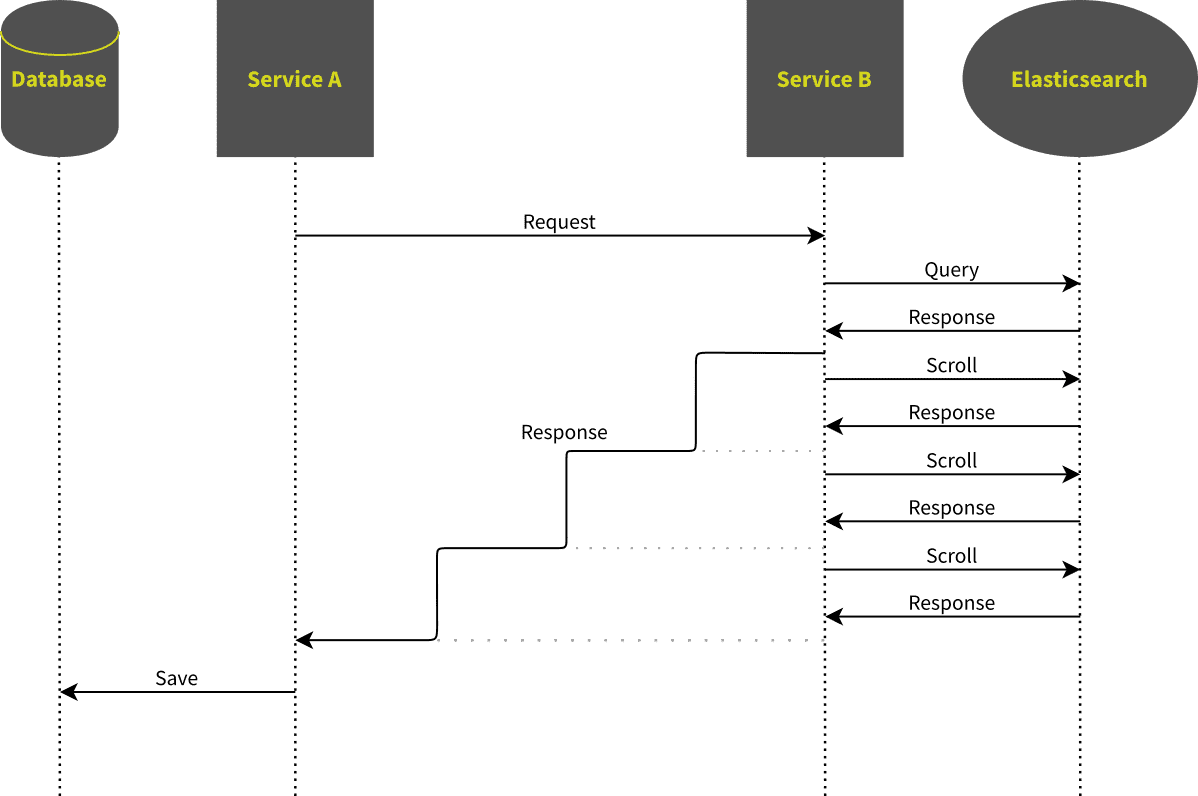
That way, the first by will be sent as soon the first page is received from Elasticsearch, which should not take more a couple of seconds, probably less. During the scroll-scan, we write the data to the response every time we receive a page of results from Elasticsearch. The great thing is that we can return the same plain JSON response as in solution 2.The only difference from the clients point of view is, that the data flows continually, without long pauses.
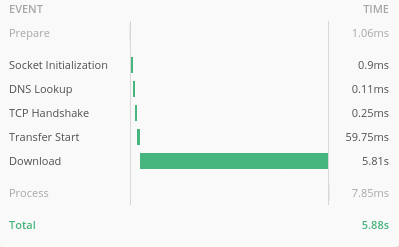
The benchmarks show the time-to-first-byte is now minimal and most of the time is spent downloading the content.
We can implement solution 4 in the following steps, each of which is explained in more details below:
- Create an
Iteratorthat uses the Scroll API to iterate the result pages - Convert the
Iteratorto aStreamor search hits. - Use the resulting stream in response, so that Jackson converts the stream to a JSON array.
In some cases, we may also need to tweak the JSON rendering, to update the response output more often.
Disclaimer: The following examples are kept intentionally simple. For example, we use lomboks @SneakyThrows to
avoid unnecessary try-catch blocks.
An iterator for scroll-scans
If you are not familiar with Elasticsearch’s Scroll API, I suggest you read the documentation for scroll-scans first. We use the Java High Level Rest Client to query Elasticsearch.
public class ScrollScanIterator implements Iterator<SearchHits>, AutoCloseable {
public static final TimeValue KEEP_ALIVE = TimeValue.timeValueMinutes(10);
public final RestHighLevelClient client;
public final SearchRequest searchRequest;
private SearchResponse lastResponse;
public ScrollScanIterator(RestHighLevelClient client, SearchRequest searchRequest) {
this.client = client;
this.searchRequest = searchRequest;
}
@Override
public boolean hasNext() {
return lastResponse == null || lastResponse.getHits().getHits().length > 0;
}
@SneakyThrows
@Override
public SearchHits next() {
if (!hasNext()) {
throw new NoSuchElementException();
}
if (lastResponse == null) {
lastResponse = getInitialResponse();
} else {
lastResponse = getNextScrollResponse();
}
return lastResponse.getHits();
}
private SearchResponse getInitialResponse() throws IOException {
SearchRequest initialSearchRequest = new SearchRequest(searchRequest).scroll(KEEP_ALIVE);
return client.search(initialSearchRequest, RequestOptions.DEFAULT);
}
private SearchResponse getNextScrollResponse() throws IOException {
SearchScrollRequest scrollRequest = new SearchScrollRequest(lastResponse.getScrollId()).scroll(KEEP_ALIVE);
return client.scroll(scrollRequest, RequestOptions.DEFAULT);
}
@SneakyThrows
public void close() {
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(lastResponse.getScrollId());
client.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);
}
}This class essentially takes as constructor-parameter:
- a RestHighLevelClient, which is used to send requests to Elasticsearch
- a SearchRequest, which contains the query, page-size, sorting and other parameters
When the next()-method is called, it will either perform the initial search-request, extended by the “scroll”-option,
or it will perform the next scroll request and receive and additional set of data. It then returns the page of
search results, which is contained in the SearchHits class.
We also make the class AutoClosable and implement a close method the clears the scroll from Elasticsearch. Elasticsearch
can only hold a limited number of scroll-scans open, as it is very resource intensive. Our scroll-scan is automatically
discarded after ten minutes of inactivity, but it is better to clear the scroll immediately, when an error occurs.
By implementing AutoClosable we can use the iterator in a try-with-resources block.
With this class, we can easily iterate scroll-scan page-by-page. Since we don’t want to return a collection of pages, but a collection of hits, we must flatten this structure. Furthermore, there are almost always some transformations to apply, because we usually do not want to return the plain Elasticsearch data-structures, but our own format.
Converting the iterator to a stream
In order to easily apply transformations, we convert the iterator to a string.
public Stream<PostalCode> streamAllPostalCodesByScrollScan(String countryIso2) {
SearchRequest searchRequest = ... // create SearchRequest here
return streamSearchHits(searchRequest);
}
private Stream<PostalCode> streamSearchHits(SearchRequest searchRequest) {
ScrollScanIterator scrollScanIterator = new ScrollScanIterator(client, searchRequest);
Spliterator<SearchHits> spliterator = Spliterators.spliteratorUnknownSize(scrollScanIterator, 0);
return StreamSupport.stream(spliterator, false)
.onClose(scrollScanIterator::close)
.flatMap(searchHits -> Stream.of(searchHits.getHits()))
.map(this::searchHitToPostalCode);
}
@SneakyThrows
private PostalCode searchHitToPostalCode(SearchHit searchHit) {
return objectMapper.readValue(searchHit.getSourceAsString(), PostalCode.class);
}We first convert the Iterator to a Spliterator and then use the Spliterator to create a stream. We use flatMap
to convert the stream of pages to a stream of hits. Then we convert the Elasticsearch-hits to our own custom
domain model class (using Jackson to deserialize the JSON of each hit).
The onClose-handler is set for the stream, so that the scroll is cleared when the stream is closed.
Using Jackson to render the converted streams to JSON on-the-fly
In a Spring Boot RestController, you can just return the Stream from a mapping method.
@GetMapping("/postal-codes/{country}")
public Stream<PostalCode> fetchAllStreamed(@PathVariable("country") String countryIso2) {
return postalCodeElasticSearchService.streamAllPostalCodesByScrollScan(countryIso2);
}This will result JSON response that contains a JSON-array as body. Usually, it is a good practice, not to return arrays directly. If you wrap the array with an object, you are more flexible later, when you want to return other meta-data in addition to the hits. So, you can also include the Stream as property in your response class:
@Data
public class PostalCodeResponse {
private final Stream<PostalCode> postalCodes;
}
// ... and in the controller ...
@GetMapping("/postal-codes/{country}")
public PostalCodeResponse fetchAllStreamedAsProperty(@PathVariable("country") String countryIso2) {
return new PostalCodeResponse(postalCodeElasticSearchService.streamAllPostalCodesByScrollScan(countryIso2));
}Forcing buffer flushes while streaming
There is one last problem that we may face now: The OutputStream of our endpoints is buffered. The postal-code example does not suffer from that, because each entry is rather large, so the buffer is flushed quite often. But what if we only stream numbers, and they take a lot of time to compute.
We can simulate this with the following controller methods
@GetMapping("/slowNumbers/plain")
public Stream<Integer> streamNumbersSlowly() {
return IntStream.range(0, 10).mapToObj(this::sleep);
}
@SneakyThrows
private int sleep(int number) {
Thread.sleep(1000);
return number;
}When we access this endpoint, even though we return a stream, the endpoint will wait ten seconds and then serve a complete JSON-array of the numbers 0 to 9. This is the case, because the buffer is not full, and therefore not flushed until the whole response is computed.
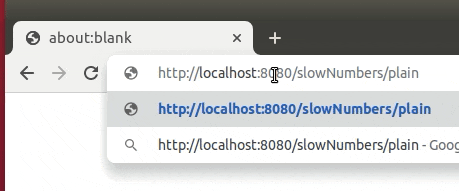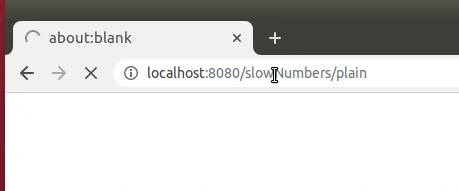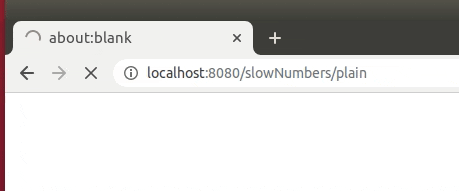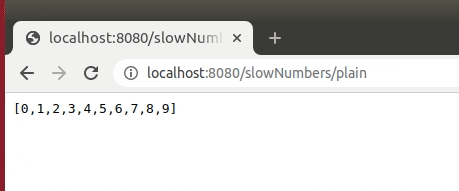
We can ensure that the stream is flushed regularly, by implementing a custom serialization logic for the stream. This can be done by registering a serializer with the object mapper.
Or we can create a wrapper object that the JsonSerializable-interface, so Jackson will call the serialize()-method to
convert the object to JSON.
public class AutoFlushingStreamWrapper<T> implements JsonSerializable {
private final Supplier<Stream<T>> streamSupplier;
public AutoFlushingStreamWrapper(Supplier<Stream<T>> streamSupplier) {
this.streamSupplier = streamSupplier;
}
@Override
public void serialize(JsonGenerator jsonGenerator, SerializerProvider serializerProvider) throws IOException {
jsonGenerator.writeStartArray();
try (Stream<T> stream = streamSupplier.get()) {
writeAndFlushRegularly(jsonGenerator, serializerProvider, stream);
}
jsonGenerator.writeEndArray();
}
private void writeAndFlushRegularly(JsonGenerator jsonGenerator, SerializerProvider serializerProvider, Stream<T> stream) throws IOException {
Iterator<T> iterator = stream.iterator();
while (iterator.hasNext()) {
serializerProvider.defaultSerializeValue(iterator.next(), jsonGenerator);
jsonGenerator.flush();
}
}
@Override
public void serializeWithType(JsonGenerator jsonGenerator, SerializerProvider serializerProvider, TypeSerializer typeSerializer) throws IOException {
serialize(jsonGenerator, serializerProvider);
}
}The serialize()-method fetches the stream in a try-with-resources to ensure that it is closed afterwards. It then
iterates the stream and calls flush() after rendering each entry. We can then enhance our controller like this:
@GetMapping("/slowNumbers/wrapped")
public AutoFlushingStreamWrapper<Integer> streamNumbersSlowlyWithWrapper() {
return new AutoFlushingStreamWrapper<>(this::streamNumbersSlowly);
}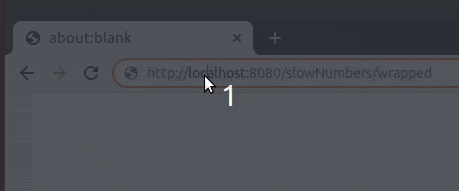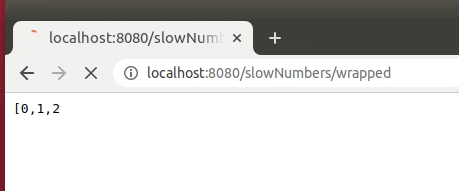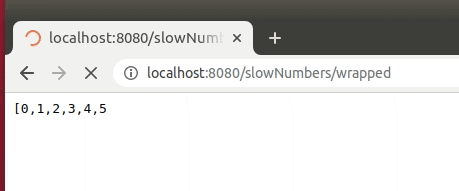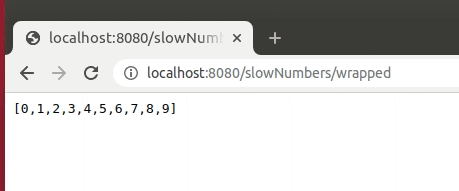
Please be aware, that this approach slows down the rendering, so we should not flush after every entry. Instead, we should schedule flushes regularly (i.e., every 2 seconds).
Conclusion
In this post, we have outlined the building-blocks for implementing an endpoint that streams data from Elasticsearch and returns it as JSON object, avoiding read-timeouts without destroying the format of the returned response. We have also shown that the response buffer can spoil that effort and how the buffering can be adapted to reduce delays between response writes.
Links
- Example-application with the code-samples used in this blog.
- Scroll scan API
- Elasticsearch High Level Java Client
- Tutorial on customizing Jackson serialization.
About the examples
ElasticSearch’s “Java REST Client” has been deprecated as of version 7.15. I tried to rewrite the examples in this post to use the new “Java API Client”, but the resulting program did not run due to conflicting dependency versions. Since this is just a blog post, I decided to leave it like it is. If you are interested in the new version, you can have a look at the java-api-client branch of the example repository.
Verfasst von:
